Deep learning has become an integral part of our everyday life. We use it every day without realizing it. For example, when Google automatically translates an entire web page between languages in a matter of seconds or when you unlock your phone with facial recognition, all of this is a product of deep learning.
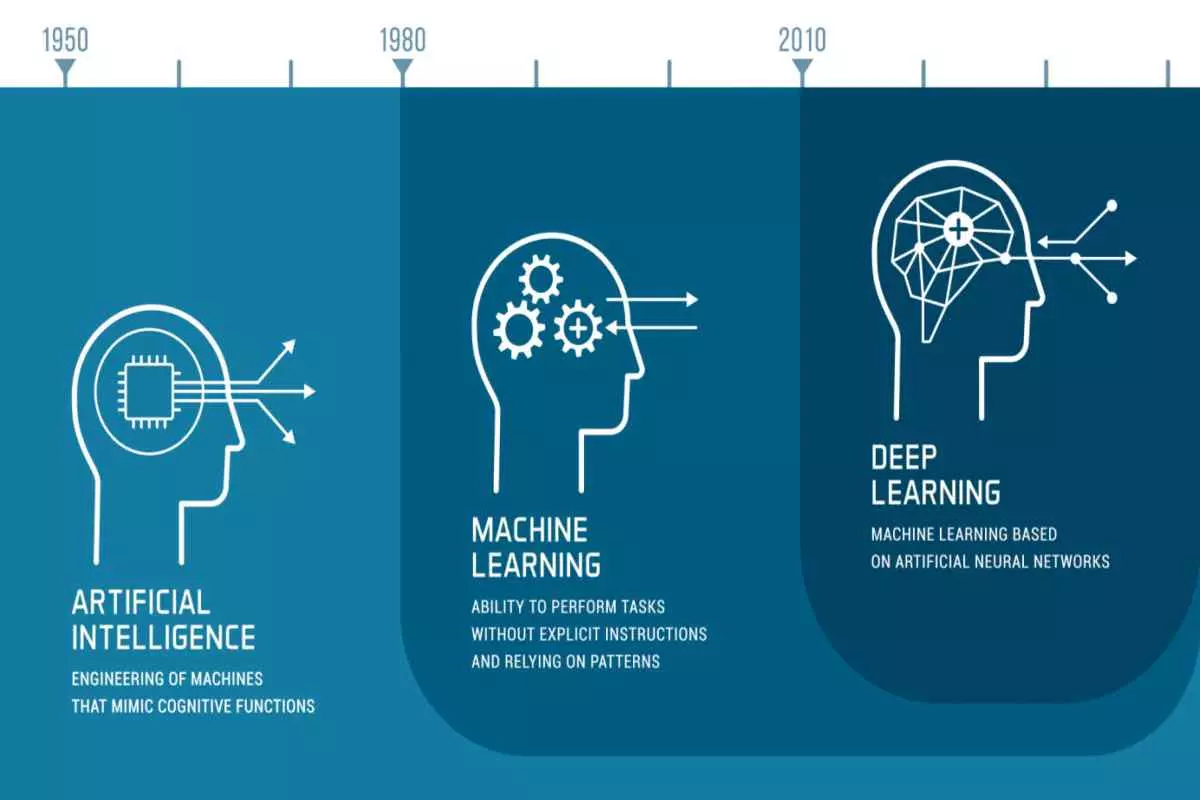
Deep learning is a subset of machine learning (ML), which is a subset of artificial intelligence (AI). AI is a technique that enables a machine to mimic human behavior, whereas machine learning is a technique to achieve AI through algorithms trained with data. At the same time, data science is the domain that covers AI, machine learning, and deep learning.
Deep learning is a machine learning technique inspired by the structure of the human brain. Let’s understand deep learning, the models used, and how it differs from machine learning.
Deep learning is a machine learning training model that works based on the structure and function of a human brain. The word “deep” refers to the multiple complicated layers or points of transformation used for data processing to create algorithms.
The system that allows communication between the layers is called the neural network. A neural network is a framework that combines various machine learning algorithms for solving certain types of tasks.
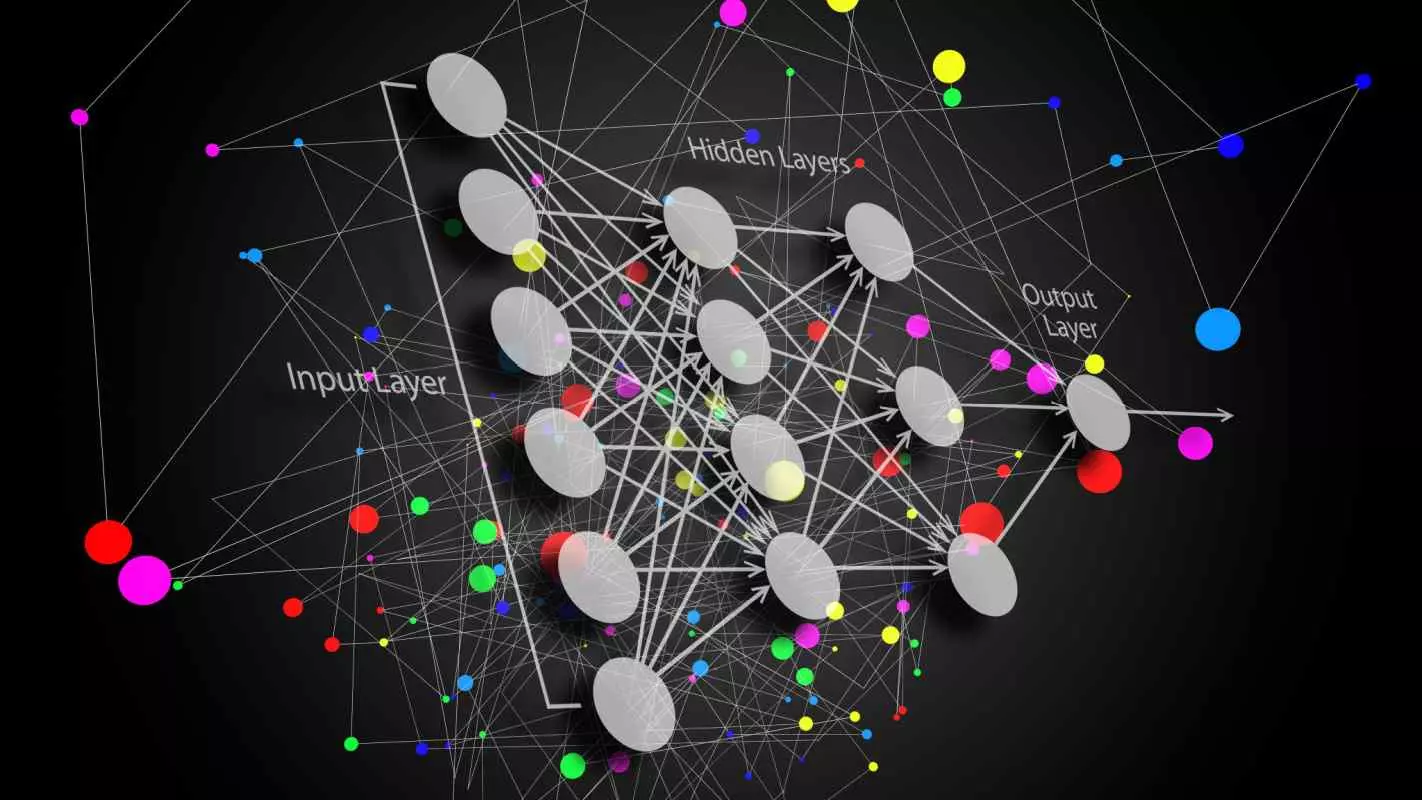
Learning programs require access to tremendous amounts of training data and processing power. The model is trained to create accurate predictive models from huge sets of unlabeled and unstructured data. In other words, a deep learning system is a vast neural network trained using a tremendous amount of data.
To better understand how deep learning works and how it is similar to the human brain, let’s imagine a toddler learning to identify a dog. A toddler learns what a dog looks like by learning the features that all dogs typically possess.
For instance, data engineers provide the model with training data, and the program uses the information to create a feature set for dogs and build a predictive model. In the beginning, the model might predict that anything in an image with four legs, fur, whiskers, and a tail will be labeled as a dog by looking at the patterns of pixels in the digital data.
However, the predictive model becomes more complex and accurate with each iteration. It also requires vast amounts of data and time to become more accurate. Unlike a human brain, deep learning algorithms can accurately sort through millions of images in a training set within a few minutes.
A variety of strategies can be used to build strong deep-learning models. Among these methods are:
A typical neural network comprises the following node layers: an input node layer, multiple hidden layers, and an output layer. These neural networks, called artificial neural networks, reflect the behavior of the human brain, which allows computer programs to recognize patterns and solve different problems.
Neural networks rely on massive amounts of training data to learn and improve their accuracy over time. Data scientists leverage supervised learning on labeled data sets to train the algorithm. The neurons are connected by lines called synapses. Each synapse has a weight determined by the activation numbers. The bigger the weight, the more dominant it will be in the next neural net layer.
There are multiple types of deep learning architectures or neural networks. For example, convolutional neural networks (CNNs) have a unique architecture for identifying patterns like image recognition. On the other hand, recurrent neural networks (RNNs) are identified by their feedback loops. They are primarily leveraged using time series data to predict future events like sales forecasting.
By now, we have a great understanding that deep learning processes information like the human brain. As a result, it can be applied to many tasks to help complete them faster than a human being. Use cases for deep learning include different types of big data analytics applications, from medical diagnoses and stock market trading signals to image recognition tools and speech recognition software.
Deep learning is currently being used in the following fields:
Image Classification: Image search systems, popularly used by Facebook and Google, use deep learning for image classification, automatic tagging, and labeling the face with the proper name.
Object Recognition: Deep learning is also used to recognize objects within images. For example, Samsung’s Bixby Vision allows you to use your camera to scan and search for relevant information on the objects and places around you.
After reviewing an object, users can utilize Bixby Vision’s image search function to locate it online. Bixby Vision’s advanced optical character recognition technology also allows users to scan and translate languages via Google’s translation database.
Speech Recognition: Speech recognition allows for the translation of spoken words into text. The most famous examples of speech recognition software include smart speakers like Alexa and Google Translate, where the latter can translate the written text of more than 100 languages.
Medical Field: One crucial application of deep learning is in the medical field, particularly radiology. Convolutional networks can help detect anomalies like tumors and cancer using data from MRI, fMRI, ECG, and CT scans.
Financial Field: In finance, deep learning can make stock buying and selling predictions based on market data streams, portfolio allocations, and risk profiles.
Digital Advertising: In digital advertising, deep learning is used to segment users by purchase history to offer relevant and personalized ads in real time. Deep nets can optimally learn to bid for ad space on a web page based on historical ad price data and conversion rates.
Fraud Detection: Deep learning uses multiple data sources to flag a transaction as fraudulent in real-time and uses AI-driven risk modeling that adapts to shifts in spending.
Customer Intelligence: Deep learning gathers and analyzes customer information to determine the best upselling strategies.
Agriculture: Deep learning uses satellite feeds and sensor data to identify problematic environmental conditions in agriculture. This includes predicting the best crops to grow, recognizing crop disease faster, and fighting it better.
The most significant limitation of deep learning models is that they learn through observation. Hence, they do not learn in a generalizable way. The models only know what was in the training data, which is often not representative of the broader functional area. For instance, if a model has been trained on photos of cats and dogs, it will not be able to predict another animal that has similar features accurately.
Another limitation of deep learning is the issue of biases. If the model trains on data that contains biases, it will reproduce those biases in its predictions. For example, suppose data scientists develop a voice assistant and train it with the voices of people from a particular region. In that case, the model may have difficulty understanding the dialect or accents used in that region.
The learning rate of a deep learning model controls how quickly the model adapts to the problem. Nonetheless, this can also become a significant challenge to deep learning models. For example, if the learning rate is large, the model will learn faster but produce less-than-optimal solutions. On the other hand, if the rate is too small, the process may take longer to train and make it harder to reach a solution.
Therefore, deep learning models require multicore high-performing graphics processing units (GPUs) to ensure improved efficiency and decreased time consumption. In addition, other hardware requirements include random access memory (RAM), a hard disk drive (HDD), and a RAM-based solid-state drive (SSD). However, these hardware requirements are expensive and use a lot of energy, creating limitations.
Deep learning models cannot handle multitasking, meaning that they can deliver efficient and accurate solutions to only one specific problem. Even solving a similar issue would require retraining the system.
Noted earlier is that machine learning and deep learning are both types of AI, and deep learning is a type of machine learning. In other words, deep learning is a sub-type of machine learning which is itself a sub-type of AI. The difference between these two types of AI is in the data presented in the AI model.
Typically, a machine learning approach will require structured data, that is, data that contains labels for the things you want to identify. So, for example, if data scientists were to feed the model with images of dogs and cats, the user would need to sit down and label each image as either a dog or a cat. In doing so, the machine learning algorithm could learn the difference between those two species. If the model performs inadequately, it is up to the user to adjust the relevant parameters and try again.
Now, deep learning is a little bit different. While training a model, adjustments are not required by the user as the neural network can score the results independently and adjust accordingly without human intervention. So, for example, if you had the same dataset but didn’t label any images, the deep learning algorithm would figure out the difference between the two categories and group them. However, that independence comes at the cost of having a much higher volume of data to train the machine.
Data science is a broad domain that covers AI, ML, and deep learning. Data science is a field of study that uses modern tools and techniques to process, clean, analyze, and visualize large datasets.
The data collected by companies can be in various formats. For example, it could be structured, semi-structured, or unstructured. Data science can improve your business by getting valuable information from this data. Data scientists are professionals who convert raw data into meaningful insights, find market patterns, and help organizations make important decisions.
Data science is divided into six steps:
Machine learning is a field of AI that allows machines to learn from vast volumes of data and make intelligent decisions on their own using algorithms. It gives computers the ability to learn without being explicitly programmed. Machine learning helps to train models that learn automatically and improve with experience.
ML is divided into seven steps:
Deep learning, machine learning, and data science are sometimes used interchangeably. Nonetheless, they are not the same.
Data science represents the entire process of finding meaning in data. Machine learning algorithms leverage the data from data science to make predictions. Deep learning is a machine learning technique that attempts to improve decision-making. It eliminates some of the data pre-processing that is involved with machine learning. These algorithms can process unstructured data, like text and images, and automate feature extraction independent from human experts.
Try our real-time predictive modeling engine and create your first custom model in five minutes – no coding necessary!


