Let’s take a crash course in data science terminology.
At Plat.AI, we take data science and the required tools to deliver performance and outcomes catered to your organizational needs adequately. To best understand what we do, we define some key concepts below in a non-technical way so that you can be empowered to know precisely how data science and Plat.AI can benefit your business.

Data: Any piece of information or characteristic can be numeric or descriptive. An example of data can be a customer’s age, gender, and ethnicity. It can also be product revenue and retention rates. It’s been estimated that up to 70% of any organization’s data is underutilized! At Plat.AI, we believe in the power of your data, and it is our mission to maximize our understanding of it to help your organization achieve its goals.
Data Science: An emerging, multidisciplinary approach conveying information obtained from data in an impactful way. Though not necessarily a new field, it combines statistics, computer science, programming, and related subjects as it relates to optimizing existing and new data processes to benefit current and future organizational needs positively.
Statistics: Whereas mathematics can be considered a known or physical, numerical world, statistics can be thought of as its unknown counterpart. Traditional statistics deal with inferences, conceptualization, and generalizations of findings for broad or complete populations based on sampling from smaller samples. Until recently, big data and the necessary computing power to make substantive analyses were theorized but never implemented. Advances in computing power and more and more companies accumulating more critical data, in turn, have allowed data science professionals to apply mathematical practices at a massive scale. At Plat.AI, we embrace the new possibilities possible with data science in addition to the core statistical theory foundational to it. We will always consider all potential solutions to any organizational problem, regardless of field or methodological maturity.
Machine Learning: Sometimes abbreviated as ML, is the study of algorithms, or a set of fine, well-defined instructions designed to perform automated tasks, that can be improved through experience. Generally, these algorithms are used to build mathematical/computational models based on training data. These models are trained to look for patterns to predict or make other decisions without being necessarily programmed to do so, and the accuracy of decisions can be evaluated with “testing” data, usually the desired outcome that the algorithms are trained to execute or help predict. In some ways, machine learning is computational statistics and is also considered a subfield of artificial intelligence. In a business or organizational context, it is also referred to as predictive modeling or analytics. Another way to think of ML: it is to data science what physics is to civil and other forms of engineering.
At Plat.AI, we’re ready to deploy ML traditionally used in data science yet are also keen on best tackling unique and industry-specific problems. Other modeling approaches considered can be psychometric and econometric, or, respectively, modeling human and economic factors. At Plat.AI, it is our mission to help you identify and improve existing and future needs. Our goal is to automate decision-making with the use of sophisticated modeling techniques, not only potentially eliminating human tasks but also improving and streamlining decision-making processes.
Data Visualization: Summary and representation of information obtained from data. More artistic, the main goal is to present findings and graphics in a digestible manner for the intended audience.
Supervised Learning: ML application with a defined target about data available for modeling. The predictive modeling approaches usually fall under supervised learning, given they aim to predict a previously described outcome given an existing array of data. We can think of supervised learning as a more specialized approaches.
An example of a supervised learning ML algorithm can be a model that targets retention explicitly in existing customers. At Plat.AI, such a model can be built! All that would be needed is data on previous customers with the target feature. More specifically, past customer data would be required, including features like age, income, etc. in addition to whether the customer was retained or not. This data can be used to train the model and, if proven accurate, could be implemented in real-time decision-making. Essentially, we would be training a model on previously “supervised” customer data to help with a prediction for a new customer, the prediction being whatever it is your business intends to do more effectively.
Unsupervised Learning: ML application where there is no defined target about data available for modeling. These algorithms usually don’t fall under predictive modeling and are concerned more with grouping or clustering approaches. Another use for them is dimensionality reduction or grouping extensive data that may not necessarily be all relevant to smaller, more key groups. We can think of unsupervised learning as a more exploratory approach. Commonly used techniques include k-means clustering and principal component analysis, both aiming to group features within data into fewer groups.
Regression: Perhaps one of the most used supervised ML techniques, broadly defined as supervised learning where we make a few theoretical assumptions beforehand, more relevant being the nature of the target. Linear regression assumes a numeric goal, like expected profit, or another numerical outcome like age, and attempts to predict it with the provided data. Nonlinear or logistic regression assumes a binary target, like retention or no retention, and also aims to predict it. Both methods are commonly used as predictive models and work nicely in that direct relations between the features used to build them, and the targets can be assessed and interpreted.
Classification: A more roughly defined technique; generally, the aim is to classify using some modeling technique. We could classify the probability of retention using nonlinear regression and a cutoff. Say we use a model to predict chances of retention; anything estimated at 75% or higher can be labeled retained, and anything below not kept. We could also classify written text like product reviews into positive, negative, or neutral using deep learning techniques. In both these cases, the type of learning would be supervised. However, classification can also be unsupervised in the case of clustering or principal component analysis. At Plat.AI, we believe classification techniques are impactful regardless of industry. They can help streamline operational resources, including providing insight into things like marketing campaigns. By having your data work for your business needs, you maximize your resources and gain valuable insights.
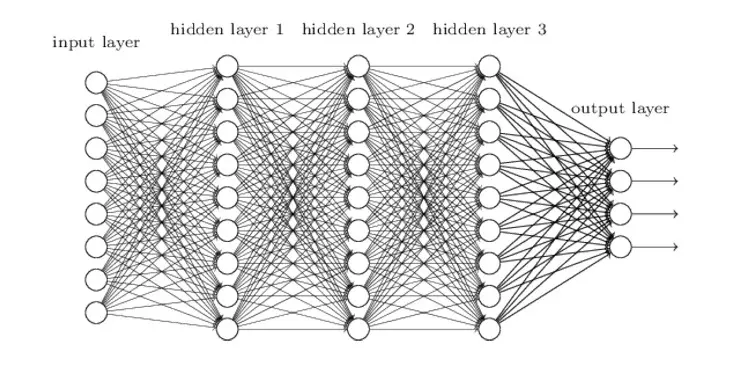
Deep Learning: A flagship and more contemporary data science ML technique commonly referred to as (artificial) neural networks. The theoretical basis for these types of models has been around since the 1950s, the basic idea being they imitate rather crudely how we believe neurons and learning in the brain functions. It is referred to as “deep learning” due to the successive layers of artificial neurons in their architecture, interconnected depending on the aim of the model. All, however, have a basic structure, with input (data) on one end and output or decision on the other, between the two countless “neurons” or weights connecting the two endpoints. Most of the artificial intelligence at the forefront of projects like self-driving cars, voice assistants, computer image recognition, and others implement deep learning models in their software computation. The fundamental idea of deep learning is the nonlinear transformation from input space (data) to feature area (output or intended target), with multiple layers of change, increasing the capacity of nonlinearity features.
A simple illustration of this idea: Say you have red and blue points (input) on a sheet of paper, and you want to draw a line (output) separating the two colors. A neural network can allow us to represent the sheet (two-dimensional) of paper as a cube (three-dimensional) to understand better and “draw” the division line between red and blue points with greater precision than we would get with traditional models.
It is rather challenging to do something like this computationally. As mentioned, the theory has been around since the 1950s. Still, it wasn’t until recently that we had the necessary computing power to estimate and generate all the required components (the main ones being the estimated parameters for all the weights between the neurons) in the models to make them work in real-time. The more complex neural networks have thousands of weights, thereby needing thousands of parameters estimated, and this takes computational power and time to do effectively.
The main disadvantage of deep learning models, aside from being computationally expensive, is their lack of interpretability. Whereas in regression and other supervised learning techniques, one can directly observe and interpret the data’s relation to the target, we cannot do so with deep learning, in a way due to their complexity. As a result, they are commonly referred to as black-box techniques, meaning we get accurate and desired results but don’t know what’s in the box.
At Plat.AI, we explore and embrace all modeling techniques, including deep learning. The main criteria for our products are to determine your needs and whether something black box-like deep learning can get the job done. For example, if the target is loaned as it concerns underwriting, then deep learning may not be optimal given our desire to understand the relation between a potential loan’s personal information and loan worthiness. On the other hand, for a self-driving car, it probably matters more to have the most sophisticated ML model, interpretability, or lack thereof irrelevant if the vehicle remains accident-free.
Interpretability: Refers to the understandability of a model, or how it explains the relations explored and mapped within the data. Classic and operationally less intensive ML applications like regression and principal component analysis are interpretable. In contrast, black-box techniques in deep learning are not due to the complexity of their structure and the number of parameters. At Plat.AI, we strongly believe in fully understanding the intricate workings of all the models we implement independently of their interpretability. The more we know, the better we can help you identify and improve. If a problem calls for deep learning, then we will implement such a model, or if it calls for interpretation, then we would implement a more traditional approach.


