Building and employing a machine learning (ML) model requires extensive planning and hard work. The machine learning life cycle diagram can be divided into five main stages, all of which carry equally important considerations. A thorough understanding of this life cycle can help data scientists manage their resources and gain real-time knowledge of their progress. The five stages we will discuss in this article include planning, preparing the data, building the model, deploying it, and monitoring.
The ML lifecycle is a framework that data scientists follow to build models from scratch for everyday use. Establishing a detailed framework for model development is essential for several reasons:
The machine learning life cycle involves utilizing artificial intelligence (AI) and machine learning (ML) to build an effective machine learning project. It starts from the initial conception of a given project, moves to the development of the model, and ends with monitoring and optimizing its performance.
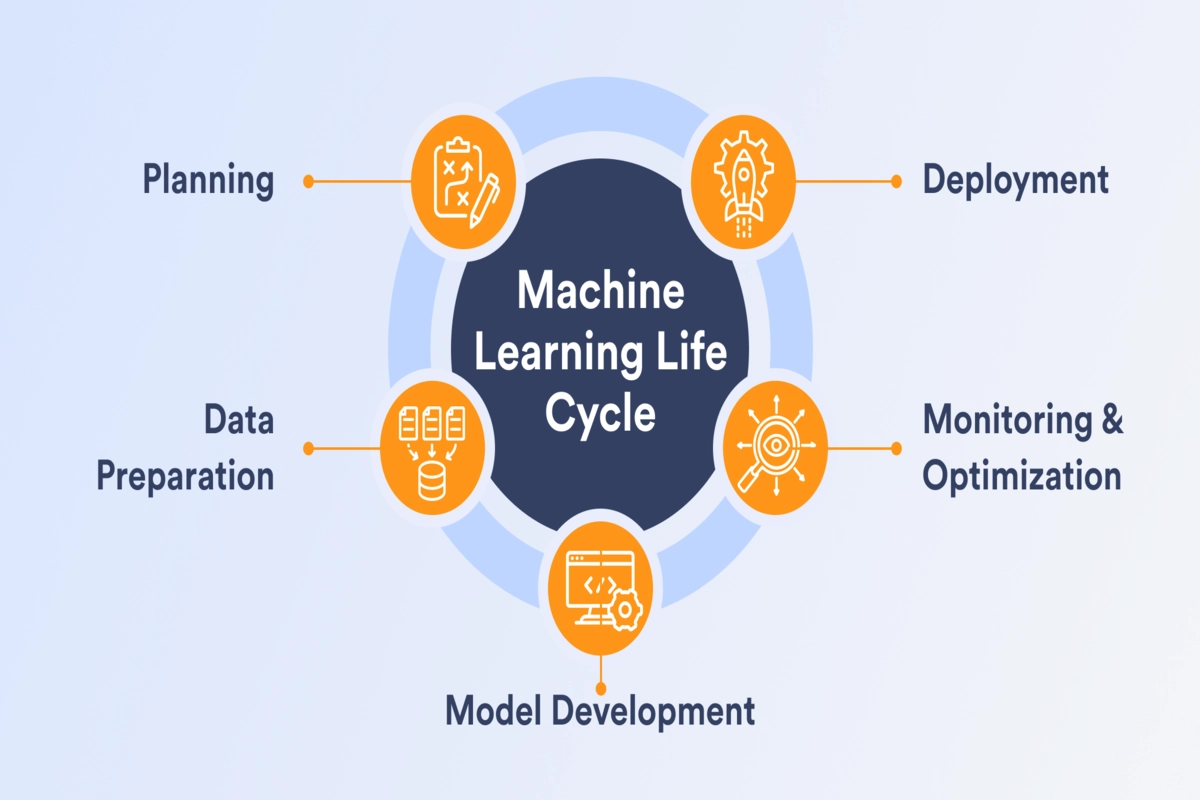
The end goal of the life cycle is to find a solution to a given problem by deploying an ML model. Like other models, a machine learning model can also degrade over time and needs constant maintenance. Thus, a model’s life cycle doesn’t end after deployment. Optimization and maintenance are vital elements to ensure that the model runs smoothly and doesn’t veer toward any bias.
That said, let’s have a detailed look at the five major stages of the ML life cycle.
Every model development initiative should start with detailed planning by defining the problems you want to solve. Model building is a resource-intensive process, and you wouldn’t want to spend your time and money on problems that can be solved in easier ways.
The second stage focuses on acquiring and polishing your data. You’re most probably going to deal with a large amount of data, so you need to make sure that it’s accurate and relevant to start building the model.
This stage is divided into several steps.
Collecting a large amount of data may be pretty costly and time-consuming, so first, try to see if you can obtain data that is already available. If you find data from several sources, you also need to merge them into a single table. However, you can also collect data yourself through multiple channels like surveys, interviews, and observations.

Data labeling refers to adding distinctive labels to raw data, such as images, videos, or text. It helps categorize your data and separate them into particular classes for easier identification in the future.
The larger your dataset, the more thoroughly your data will need to be cleaned. This is because all large datasets typically include multiple missing values or irrelevant information. Removing these before building the model will help increase the accuracy of the eventual model and reduce the chances of error and bias.
The last critical step before starting to build the model is conducting data exploration. This approach analyzes the data and presents a summary, typically using visuals. Data exploration provides a sneak peek into common patterns and helps data scientists understand the dataset better before modeling.
Once you have the data prepared, it’s time to develop the model. Model preparation is at the core of the machine learning process flow, and it involves three subpoints:
Deploying a machine learning model means putting it to work in the real world, where it can help make smarter business decisions. This step is crucial because it takes the model from the lab to practical use, making a real impact on everyday operations.
Models can be deployed in several ways. Using cloud platforms is great for scalability and easy access, while local servers are perfect for keeping everything secure and under control. Web browsers offer convenient user access through simple interfaces, and software packages integrate smoothly with existing systems. For real-time data processing, deploying on edge devices is ideal.
Once your model is deployed, there are various ways to access it. APIs allow other software programs to interact with your model, and web apps provide user-friendly interfaces. Plugins can add new features to existing software, while dashboards offer visual tools to display the model’s predictions and insights.
To ensure your model works well, you’ll need adequate technical resources. This includes enough RAM for handling data, plenty of storage for keeping all the model’s data and results, and strong computing power to ensure fast and accurate predictions.
Monitoring the model’s performance is essential. You can use A/B testing to compare its results with a control group, ensuring it’s effective. Gathering user feedback is also crucial to understand what’s working and what needs improvement.
Deploying a model can be challenging due to compatibility issues. Sometimes models need to be tweaked to work with existing systems. This stage often requires teamwork between data scientists and IT teams to get everything running smoothly.
By following these steps and collaborating effectively, you can successfully deploy machine learning models to make your business smarter and more efficient.
Maintaining and optimizing a deployed model is crucial to ensure it continues to provide accurate and reliable predictions. Over time, a model may degrade due to changes in the underlying data or external factors. To prevent this, constant monitoring and periodic optimization are necessary.
Monitoring:
Regular monitoring helps detect issues such as model drift (when the statistical properties of the target variable change) and bias (when the model unfairly favors certain outcomes). Data scientists and ML engineers use predictive analytics software to track these issues and ensure the model remains accurate. This software analyzes data trends and flags potential problems before they impact the model’s performance.
Optimization Techniques:
To enhance model accuracy, techniques such as ensemble learning (combining multiple models) and transfer learning (leveraging pre-trained models for new tasks) can be employed. Additionally, optimizing inference time and reducing computational complexity are critical for improving efficiency in production environments. This involves streamlining the model to make faster predictions without compromising accuracy.
Using Predictive Analytics:
Predictive analytics software plays a vital role in monitoring and optimization by providing insights into current trends and industry best practices. For example, it can forecast customer churn or identify potential targets for marketing campaigns. By leveraging these insights, businesses can stay ahead of the curve and make informed decisions.
Continuous Improvement:
Monitoring and optimization should be an ongoing process. Regular updates, retraining the model with new data, and integrating feedback from end-users are essential practices. This continuous loop ensures the model adapts to changing conditions and consistently delivers value.
By implementing these strategies, organizations can maintain the performance of their machine learning models, ensuring they continue to provide accurate and actionable insights over time.
To sum up, the machine learning life cycle is a standard framework that data scientists can follow to gain a deeper knowledge of machine learning model development. Management of the ML model life cycle is usually conducted around this framework, which includes everything from defining the problems to optimizing the model.


