If you’re navigating the realm of data science, you’ve probably encountered the term “machine learning pipeline.” But what exactly is it, and why is it a cornerstone in the data world?
This technology is a strategic process, steering raw data through various stages until it emerges as valuable insights. Stay with us as we dissect the inner workings of the machine learning pipeline, its benefits, the challenges it presents, and its real-life applications.
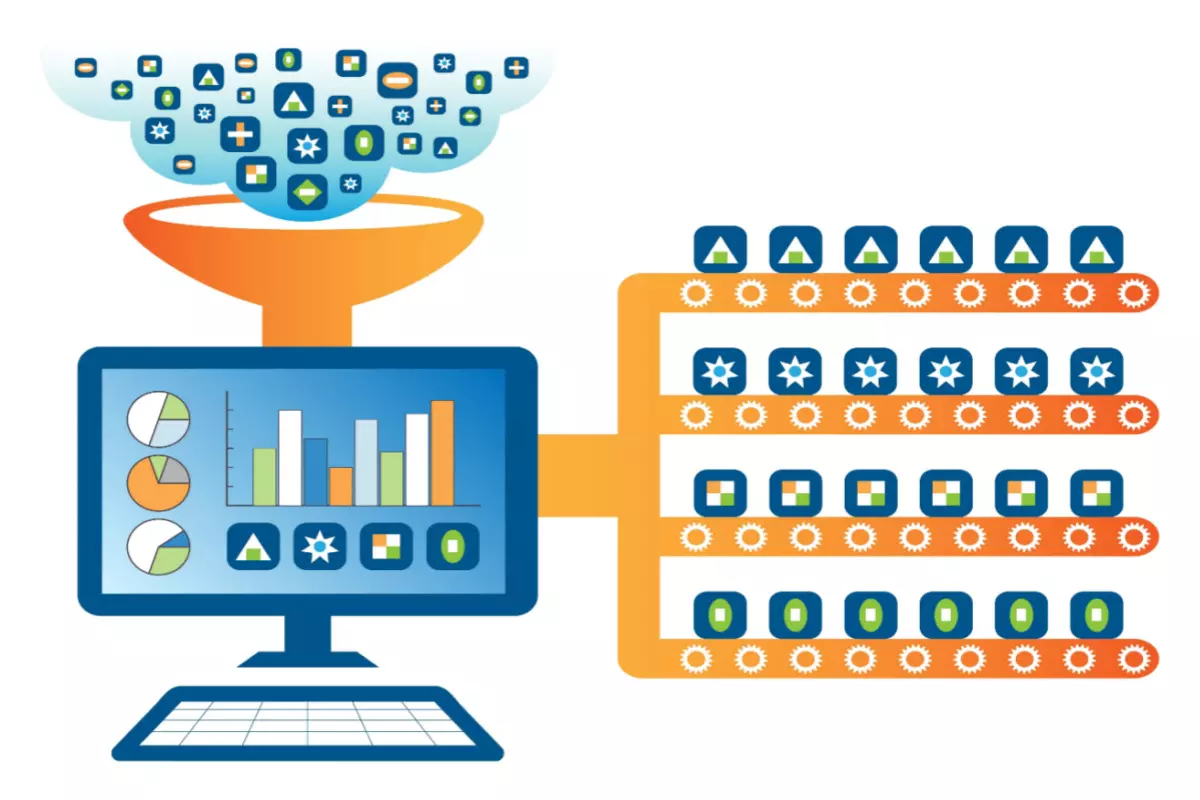
At its core, a machine learning (ML) pipeline is an automated sequence of processes that enables data to flow from its raw state to one that is refined and valuable for machine learning models.
For instance, imagine an e-commerce company that collects a broad array of raw data about its customers’ online behavior, such as browsing history, search queries, items clicked on, and so on. A machine learning pipeline can eventually turn this into organized data about average browsing time or primary interest groups, which can then be used for better predictions.
Let’s take a step back for a moment. In machine learning, we often deal with a vast amount of raw data. This data must be collected, cleaned, processed, and then used to train and evaluate machine learning models. Afterward, the models need to be deployed and monitored.
Each of these stages could be a field of study in its own right, and executing each one effectively and seamlessly could be a daunting task. This is where the machine learning pipeline steps in, bringing order and efficiency to what could otherwise be a chaotic process.
The stages in an ML pipeline may vary slightly depending on the specific task or data at hand but generally includes the following:
A well-constructed machine learning pipeline offers a host of benefits, making it a powerful tool for any data scientist or AI engineer. Its core advantages are tied to efficiency, consistency, scalability, reproducibility, and collaboration. Let’s delve deeper into each of these benefits.
Consider the process of handwriting recognition. Without a pipeline, an engineer would have to collect handwriting samples manually, clean the data, and finally deploy it. Now suppose there are 10,000 handwriting samples to process. By automating the entire process from data collection to model deployment, a pipeline eliminates the need for manual intervention at each stage. This saves time and reduces the risk of human error, making the whole process more reliable.
Imagine a company using machine learning to predict customer churn rates, which is the percentage of customers who stop doing business with an entity. If data preprocessing steps vary from month to month, the predictive performance could fluctuate inconsistently. By defining a standard sequence of steps, pipelines ensure that data is handled consistently every time. This data processing approach guarantees that the model’s insights and predictions are reliable and comparable across different runs.
As your data grows in volume or complexity, a pipeline allows you to handle this growth efficiently. Whether you’re dealing with thousands of data points or billions, a pipeline can scale to accommodate this and ensure that your models continue to perform effectively.
For example, a pipeline could help a social media platform that uses ML to recommend posts to users. As the platform’s user base grows, a scalability feature would be needed to continue generating these recommendations.
Suppose a healthcare institution uses ML to predict disease risk based on patient data. If the facility needs to make a similar prediction in the future, it should be able to reproduce the same results given the same data. A machine learning pipeline, with its standardized and automated sequence of steps, provides this reproducibility.
Finally, ML pipelines also enhance collaboration among data scientists. If one team member decides to change a preprocessing step or swap an algorithm, the whole team needs to understand the impact of these changes. Given that they establish a structured, consistent methodology, they make it easier for teams to understand and collaborate on projects. This shared understanding can significantly streamline development and troubleshooting efforts.

While machine learning pipelines are a powerful asset in AI, they also present certain challenges. The first challenge lies in designing and setting up the pipeline itself. Setting up and maintaining the pipeline can be challenging due to its complexity, the required expertise, the associated costs, and the need for continuous monitoring and updating.
It requires careful orchestration of the data processing sequence, model training, evaluation, and deployment steps. Additionally, this initial setup can require substantial investment, ranging from $10,000 for small, simple projects and much more for complex projects in large organizations.
Maintaining the pipeline is the next challenge. ML models often suffer from “concept drift,” where the relationship between input data and the target variable changes over time. A concept drift can lead to an increasing number of errors over time. In practical terms, this can result in a model’s predictions or classifications becoming less accurate. Therefore, data scientists need to continuously monitor and update the model within the pipeline, which can be resource-intensive.
Finally, integration with existing systems can also pose a challenge. Machine learning pipelines need to be compatible with the broader IT infrastructure of the organization using them. This might require custom solutions, leading to additional development time and costs.
Building a machine learning pipeline is a significant project that requires careful consideration and planning of several factors. Here are some of the main elements that data scientists and organizations should think about:
Machine learning pipelines are pivotal across many industries, driving advancements and facilitating data-driven decision-making. Here are a few illustrative use cases:
Google developed an ML pipeline to detect Diabetic Retinopathy, a diabetes complication that can lead to blindness. The pipeline preprocesses retinal images, then applies a deep learning model to identify signs of the condition. The model was trained on a large dataset of labeled images and is continually updated to maintain accuracy. The model achieved 93.72% accuracy, 97.30% sensitivity, and 92.90% specificity.
JPMorgan implemented a pipeline in their “LOXM” trading algorithm that processes vast amounts of historical trading data, applies machine learning algorithms to identify patterns, and uses this information to execute trades at optimal times. This model is consistently updated with fresh data, helping it adapt to ever-changing market conditions. The algorithmic trading bots monitor the trades to ensure they don’t reach the loss point, increasing the success rate to 97%.
Siemens has leveraged machine learning pipelines for predictive maintenance in their wind turbines. They collect data from sensors on the turbines, feed it into a pipeline where it is cleaned and normalized, and then use machine learning models to predict potential failures. As new sensor data flows in, the model is updated, ensuring accuracy and reducing unexpected failure by up to 90%.
Machine learning pipelines serve as a tool for transforming raw data into useful insights. Through automation, consistency, and scalability, they streamline and optimize processes. When setting up a pipeline, factors to consider include problem definition, data understanding, tool selection, future data growth, system integration, and regulatory compliance.
In an era of rapid digital progression, understanding and implementing machine learning pipelines can unlock new possibilities in data utilization and maintain a competitive edge.
Try our real-time predictive modeling engine and create your first custom model in five minutes – no coding necessary!


